Vector Search Using Celery and LangChain
Celery is a popular task orchestration framework written in Python. It can be used anywhere to decouple expensive and time-consuming routines from blocking application code. For example, in a service that implements AI vector search using Celery and LangChain, suppose an endpoint /search?q= calls the OpenAI embeddings API using LangChain.
This endpoint now depends on a third-party service. LangChains embedding classes are powerful, but also expensive to instantiate and better to not be created on every request.
It is better, instead, to implement a distributed vector search service using Celery and LangChain.
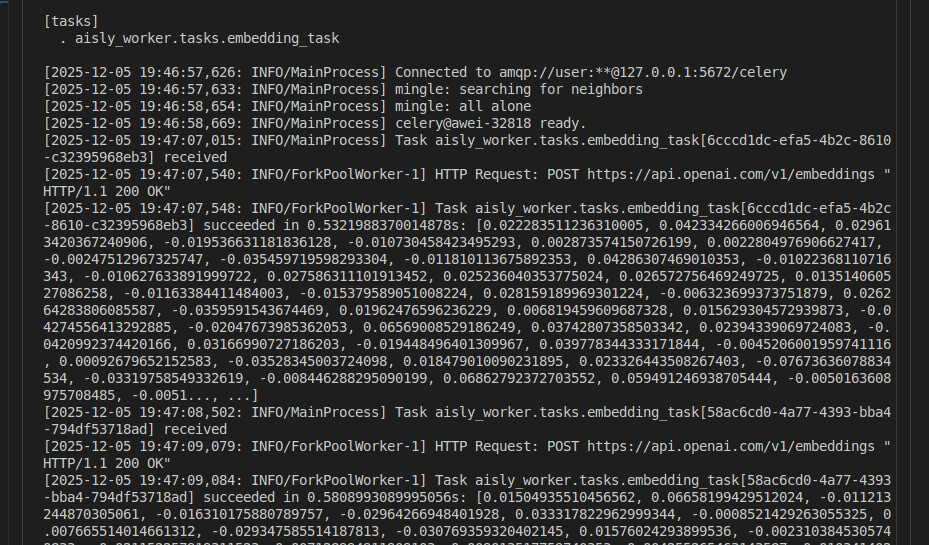
Let OpenAI embedding clients sit inside Celery workers and send them embedding queries through RabbitMQ:
"""settings.py"""
CELERY_BROKER_URL = "amqp://user:password@host:NNNN/celery"However, placing resource initialization logic directly inside celery.Task.__init__ is an anti-pattern. Nothing will explode immediately, and your tasks still run, but this pattern works against Celery’s execution model and leads to unnecessary resource creation and wasted memory in the scheduler process.
Similarity search operates in an ordered embedding space, ranking items by the distance between their vectors and the query vector.
Why? Because Celery schedulers retain a full copy of every Task object, meaning the Task class should remain a lightweight skeleton. No heavy clients, no network calls, no stateful resources attached during initialization.
So we need a safe way to initialize a resource once per worker process; not once per task instance and definitely not inside the scheduler.
Lazy-Loading
Instead, we can consider some approaches to resource initialization. There is “lazy-loading.” For a AI “model” belonging to a celery.Task object,
@property
def model(self):
# Use type(self) so subclasses get their own copy if needed
cls = type(self)
if cls._model is None:
cls._init_model()
return cls._model
initializes the resource on first access.
Since our resources belong to a class that inherits from celery.Task, these specially-initialized resources must be defined static with respect to the class.
But sometimes you do want the worker to initialize everything on process start, moreover AI workloads that retain an initialized “model” resource.
Worker Startup Signal
To initialize on start, similarly pass through the .model access method. But this time, set it on process start,
# tasks.py
import abc
from os import getenv
from types import NoneType
from typing import List
from celery import Task, signals
from dotenv import load_dotenv
from langchain_core.embeddings import Embeddings
from langchain_openai import OpenAIEmbeddings
from .celery import app
load_dotenv("./.env")
OPENAI_API_KEY = getenv("OPENAI_API_KEY")
class EmbeddingTask(Task, abc.ABC):
"""
processing of query/text strings for vector embeddings
"""
_model: object | NoneType = None
model: Embeddings
time_limit = 2.0
@classmethod
def init_resources(cls) -> NoneType:
"""initialize LangChain OpenAI client"""
cls._model = OpenAIEmbeddings(
model="text-embedding-3-small", api_key=OPENAI_API_KEY
)
@property
def model(self) -> Embeddings | NoneType:
"""access static Langchain client"""
if EmbeddingTask._model is None:
raise RuntimeError("OpenAIEmbeddings is not initialized")
return EmbeddingTask._model
@abc.abstractmethod
def run(self, *args, **kwargs): ...
@app.task(bind=True, base=EmbeddingTask)
def embedding_task(
self: EmbeddingTask, q: str, *args, _result: List[float] | NoneType = None, **kwargs
):
"""
query openai embedding model, return vector double precision
"""
if _result is not None:
return _result
return self.model.embed_query(q)where using a signal
@signals.worker_process_init.connect
def init_resources(**av): # pylint: disable=unused-argument
"""initialize worker-only resources"""
EmbeddingTask.init_resources()ensures initialization on runtime. Now
v = .tasks.embedding_task.delay(query).get()returns the query from a LangChain service that was prepared and waiting.