I implemented vector search with pgvector and Django. Vector search is everywhere now: RAG pipelines, recommendation engines, or semantic search. Even if you’re not doing anything LLM-y, embeddings are useful for fast similarity.
A user hits /search?q=:string with a query. This turns into a vector by using the OpenAI embeddings API. And we run a similarity search against a VectorField on a PostgreSQL model.
But here’s what to watch for. OpenAI’s embedding endpoint (or any external API) is a bottleneck, and Django will spin up concurrent requests if your users are fast enough. If each request instantiates a new LangChain OpenAIEmbeddings client, you hit scalability issues immediately.
Celery worker architecture for embeddings API
Celery is a popular task orchestrator in Python. You use it to coordinate worker nodes that accept long-running jobs from a producer, through a message broker like RabbitMQ.
I found it useful to perform vector search, the type you see in RAG applications. In my example, I am not doing anything LLM-y. Instead, I have a Django service that implements a /search?q=:string endpoint. The Django service passes the string to the OpenAI embeddings API, and the returned embedding is queried against a model’s pgvector field,
from django.contrib.postgres.search import SearchVectorField
from django.db import models
class Item(models.Model):
data = models.JSONField(default=dict, blank=True)
image = models.TextField(blank=True, default="")
emb = VectorField(null=True, blank=True, dimensions=1536)
...
ultimately returning related items to the user,
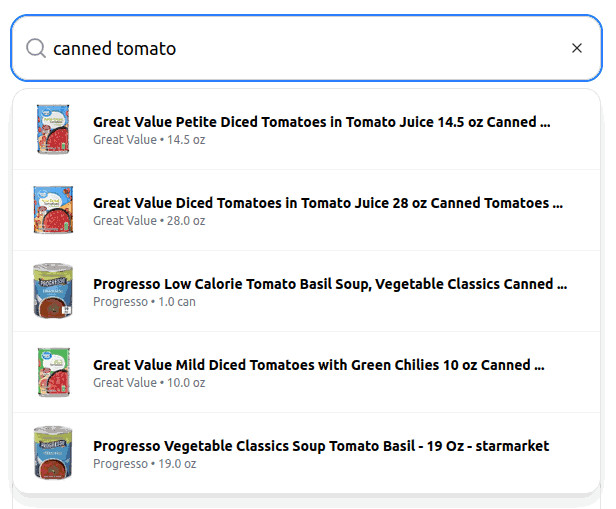
Text similarity search results for “canned tomato” uses OpenAI embeddings
Because there is one OpenAI endpoint, and potentially numerous concurrent user requests, it makes sense to pool our requests to the embeddings API. I am using the LangChain OpenAI client for vector search with pgVector and Django, so we can set up a Celery worker that initializes the client on creation.
Using LangChain OpenAIEmbeddings inside Celery tasks
There are some nuances about how Celery workers provision resources, potentially involving lazy-loading. The scheduling process retains a full copy of any @app.task object. So this object is a functional skeleton. The scheduler should initialize only its needed properties.
But because we like to walk on train tracks over here at www.alexwei.net, I will show you what not to do:
import abc
from os import getenv
from types import NoneType
from typing import List
from celery import Task
from dotenv import load_dotenv
from langchain_core.embeddings import Embeddings
from langchain_openai import OpenAIEmbeddings
from .celery import app
load_dotenv("./.env")
OPENAI_API_KEY = getenv("OPENAI_API_KEY")
class EmbeddingTask(Task, abc.ABC):
"""
processing of query/text strings for vector embeddings
"""
model: Embeddings
time_limit = 2.0
def __init__(self):
self.model = OpenAIEmbeddings(
model="text-embedding-3-small", api_key=OPENAI_API_KEY
)
@abc.abstractmethod
def run(self, *args, **kwargs): ...
@app.task(bind=True, base=EmbeddingTask)
def embedding_task(
self: EmbeddingTask, q: str, *args, _result: List[float] | NoneType = None, **kwargs
):
"""
query openai embedding model, return vector double precision
"""
if _result is not None:
return _result
return self.model.embed_query(q)
Because Task.__init__() is executed on the Celery scheduler, as well as on workers, any reference to Task.model should be through an retriever method that is available only on runtime; our scheduler does not need to retain a copy of the LangChain client, but only the structure of the Task object.
If you did not notice, we are initializing OpenAIEmbeddings object inside the Task on creation. It is better to initialize during only the worker’s runtime.
Now we can easily deploy a pool of LangChain clients via Celery workers. The systemd service:
[Unit]
Description=Celery Service for Search Suggestions
After=network.target
[Service]
User=www-data
Group=www-data
WorkingDirectory=/opt/aisly/aisly-backend
ExecStart=/opt/app/path/to/celery -A celery_app worker -l ERROR --concurrency=4 --purge
[Install]
WantedBy=multi-user.target
The remaining piece is the embedding search invocation. Observe that the .delay(query).get() invocation of the task appears synchronous:
class ItemSearchView(APIView):
def get(self, request, *args, **kwargs):
query = request.query_params.get(
"q", ""
)
...
v = aisly_worker.tasks.embedding_task.delay(query).get()however, tasks pass through Celery with OS-level resource management. So a seemingly redundant submit-retrieve cycle is a simple way to accept as many queries as Django can handle without blocking the main thread.