Here are some sample audio clips produced using the Keras-AutoVC voice conversion autoencoder.
Code
My implementation uses Keras, and is available on Github.
Many-to-many conversion between seen speakers
Source Speaker
Target Speaker
Conversion
Source Speaker
Target Speaker
Conversion
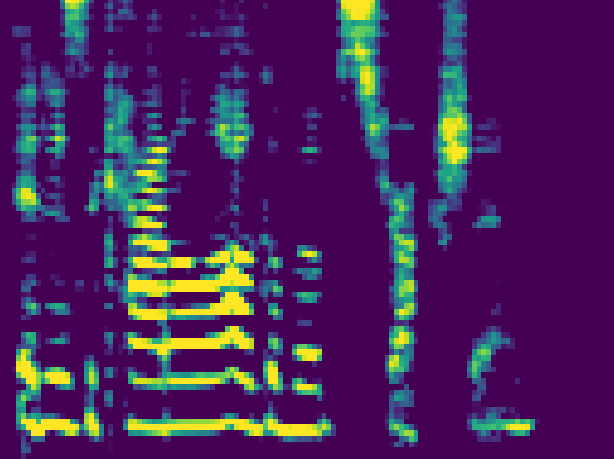
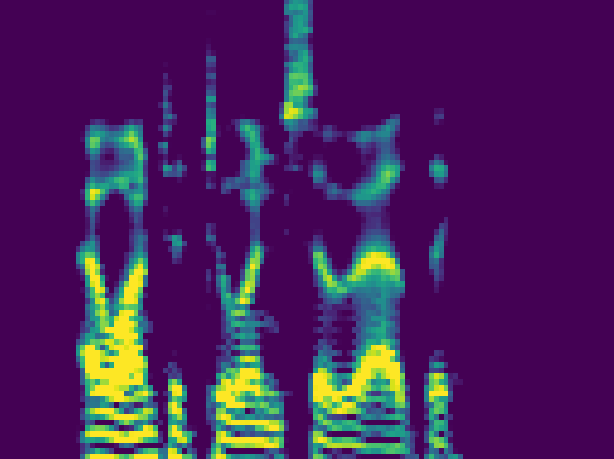
Samples from each speaker are cropped into two-second segments, and transformed into a mel-reduced spectrogram. Over the course of training, speech content is transferred between speakers. The model objective is transfer of content independent of style:
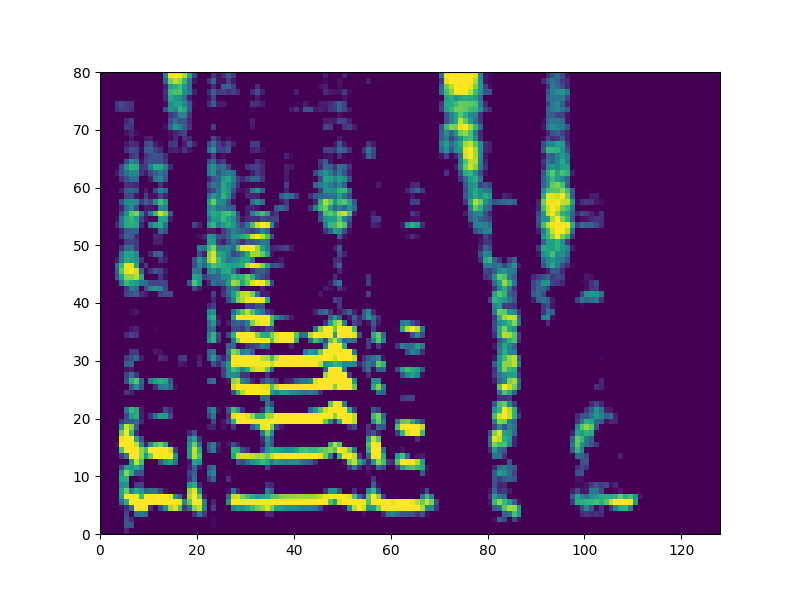
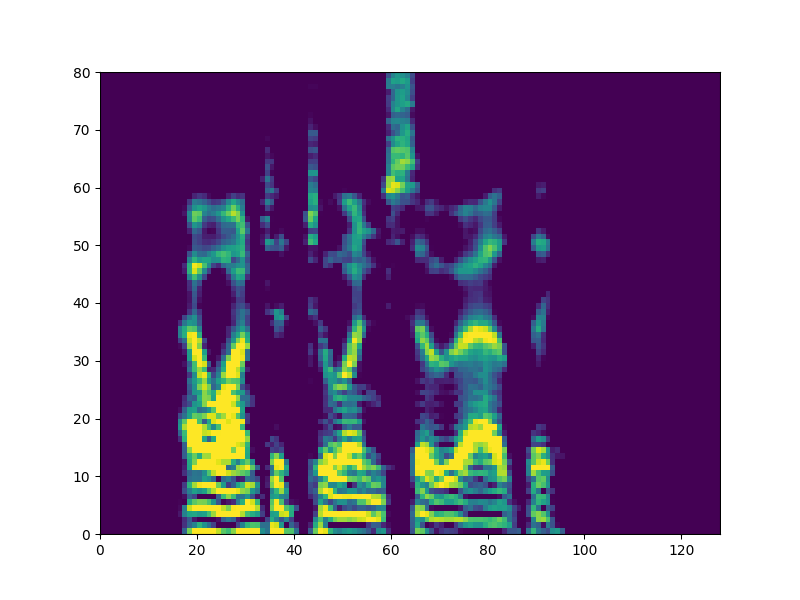
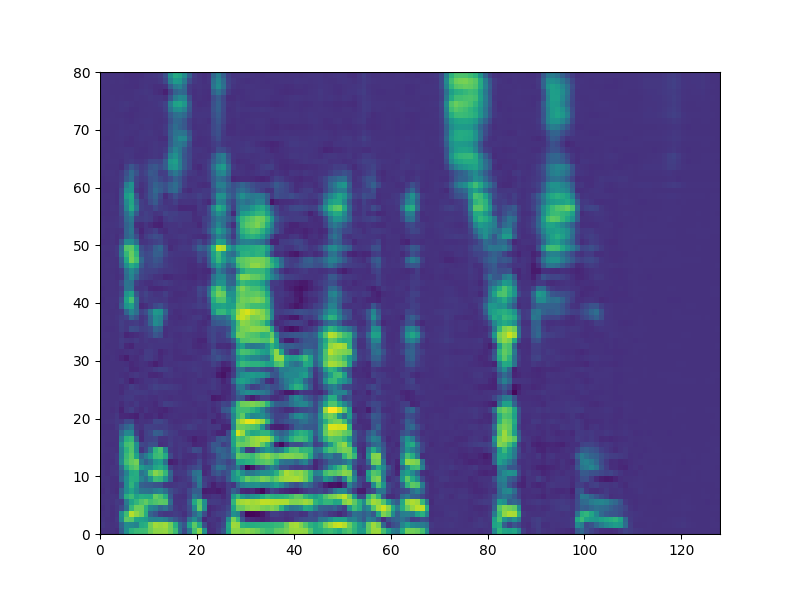
Parameters for cleaning and dynamic range compression of audio samples were determined using the CSVTK, my toolkit for compression, cleaning, and visualization of mel spectrograms.